
ETHICS, COMPUTING, AND AI | PERSPECTIVES FROM MIT
When Programs Become Unpredictable | John Guttag

John Guttag; Photo by Jon Sachs
“We should look forward to the many good things machine-learning will bring to society. But we should also insist that technologists study the risks and clearly explain them. And society as whole should take responsibility for understanding the risks and for making human-centric choices about how best to use this ever-evolving technology.”
— John Guttag, Dugald C. Jackson Professor of Computer Science and Electrical Engineering
SERIES: ETHICS, COMPUTING, AND AI | PERSPECTIVES FROM MIT
John Guttag is the Dugald C. Jackson Professor of Computer Science and Electrical Engineering at MIT. From January of 1999 through August of 2004, Professor Guttag served as Head of MIT’s Electrical Engineering and Computer Science Department. He currently leads MIT CSAIL’s Data-driven Inference Group, which develops methods for using machine learning and computer vision to improve outcomes in medicine, finance, and sports. Professor Guttag’s teaching is centered on helping students learn to apply computational modes of thought to frame problems and to guide the process of extracting useful information from data. His online courses on this topic have been taken by over a million students.
• • •
For most of the history of computing, the process of producing a useful computer program looked something like this:
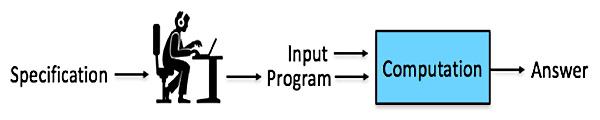
The notion of a “correct” program, was pretty simple. A program had a specification that defined a desired relationship between inputs and outputs. For example, the inputs to a tax calculator would be a person’s income, payments, deductions, etc.; and the outputs would be the amount owed. The job of a programmer was to produce code that satisfied the specification. If a program failed to meet its specification, the programmer was at fault. If the program met its specification, and users were nevertheless unhappy with the result, they could hold the authors of the specification accountable.
It was a lot like the world of Newtonian mechanics. In that world, you push down on one end of a lever, and the other end goes up. You throw a ball up in the air; it travels a parabolic path, and eventually comes down. [ADD MARKS TO EQUATION] F = ma. In short, everything is predictable. And for most of the history of computing, the same was true. One could look at the text of a program, and deduce (at least in theory) what answer it would provide when supplied with a particular input.
In the age of machine learning, things are different. For supervised machine learning the process looks something like this:
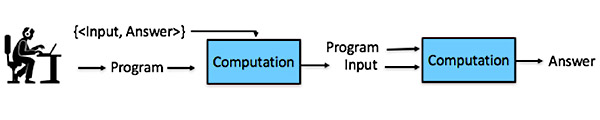
The machine learning takes place in the middle box. This box takes the program produced by the programmer and a set of input/answer pairs as training data, and produces another program, which we will refer to as a model. The model is shaped as much, or more, by the data used to build it as by the programmer who built the program that produced the model. Moreover, in practice models are often updated as new data arrives, so they are moving targets.
For example, a search engine observes which links users click on, and learns which pages to serve in future searches. And since the available links depend upon the pages chosen by the current version of the model, the next version of the model also depends upon the current version. The model is not intended to be read by humans. In general, it is not possible to examine the model and deduce how it will respond to a particular input. Consequently, it is typically the case that it is difficult to reliably predict the answer associated with a particular input, or given the answer to understand why the model provided that answer.
Giving up on perfection
Users of twenty-first century computation will have to come to grips with lack of certainty. If the behavior of a program is constantly changing and therefore we cannot fully understand how it will behave, should we feel comfortable trusting it? If a search engine occasionally makes a bad decision, not much harm is done. But what happens when machine learning is used to build programs that make recommendation with important societal implications? Will they sometimes make bad recommendations?
Almost certainly, because
- The world is a highly-varied and ever-changing place. The data used to train a model will not always be a good representation of specific examples to which the model is applied.
- While there are many different approaches to machine learning, all of them are based on optimizing an objective function. And that objective function rarely captures all of the multi-factorial aspects of the world in which we live. It is typically only a proxy for what we would really like to optimize.
More generally, we know how to measure, and therefore learn from, what happened, but not from what didn’t happen. The model will be biased by both the inputs in the training data and the answers associated with those inputs.
Imagine, for example, a program that learned to screen job applicants based upon which previous applicants were hired. It would learn a relationship between properties of applicants and who was and was not hired. Based on this relationship, it would then predict which new applicants were worth taking the time to interview. This would probably improve the efficiency of the hiring process, but would it be a good thing?
Suppose that the applicant pool used for training contained 1000 men, half of whom were well qualified, and 1 woman who happened not to be well qualified. The learning process might learn how to separate qualified and unqualified men, but conclude that all women were unqualified.
Additionally, the relationship would be learned based on who was hired, an imperfect proxy for who should have been hired. It will incorporate, and therefore perpetuate, both appropriate and inappropriate biases in the previous process. If the previous process was biased against those missing relevant skills, it will learn that. But the if the previous process was biased against minority applicants, it will learn that too. So why not use “should have been hired” as the objective function? Because we have no objective measure of that.
Moving forward
So, what is the answer? Can we avoid using machine learning for things that matter? No. That is not really an option. It is inevitable that computations based on machine learning will be used to make important decisions. And in many contexts, these decisions will often be better than decisions made by non-learning-based programs or by humans. What we can choose to do is to keep in mind the ways in which these decisions can be flawed, and rigorously monitor the consequences of these decisions. If we, as humans, don’t like the decisions a program is making, we don’t have to accept them. We can change the objective functions. We can control what data is used for learning. Etc.
Technological advances have always had risks. We shouldn’t blame the discovery that fossil fuels are flammable for global climate change. Nor should we wish that humans had never learned to make fires. What we should regret is society’s failure to anticipate and deal with the risks. We should look forward to the many good things machine-learning will bring to society. But we should also insist that technologists study the risks and clearly explain them. And society as whole should take responsibility for understanding the risks and for making human-centric choices about how best to use this ever-evolving technology.
Suggested links
Series:
Ethics, Computing, and AI | Perspectives from MIT
John Guttag:
Website
MIT Department of Electrical Engineering and Computer Science (EECS)
MIT Computer Science and Artificial Intellignce Lab (CSAIL)
Ethics, Computing and AI series prepared by MIT SHASS Communications
Office of Dean Melissa Nobles
MIT School of Humanities, Arts, and Social Sciences
Series Editor and Designer: Emily Hiestand, Communication Director
Series Co-Editor: Kathryn O'Neill, Assoc News Manager, SHASS Communications
Published 18 February 2019